とても大事なコードの計算量(big O)の話
計算量(big(O))とは?
今回は、コーディングインタビューに挑むにあたって、ある意味最も大事な概念となる計算量測定(big(O))の考え方について解説を行います。コードの計算量は、big(O)という指標で表される事が多く、こちらは「ビッグオー」や「ランダウの記号」等と言われます。以降表記はbig(O)で統一をすることにします。
big(O)は、コーディングインタビュー中で常に意識をしておく大事なポイントにもなりますが、実務においても非常に役に立ちbig(O)を意識しないコードを書いていると、不用意にリソースを無駄遣いし、Webアプリであればページのロードに時間がかかってしまう等の弊害が起きたり、データ分析系のプロジェクトであれば、分析の時間がかかりすぎてしまい、分析が完了しない等の多くの弊害を生む原因となります。
big(O)の計算方法
それでは、具体的にbig(O)の計算方法の解説を進めて行きます。まず、表記の記述方法ですが、計算量毎に、O(1)やO(N)等、O記号を書き、その中に計算量の値を指定して、コードの計算量を明記します。
とても単純に解説すると、値の代入や、参照等の場合はO(1)となり、for文やwhile文等の繰り返しの制御文がある場合はO(N)、繰り返しのループの中にループがある場合はO(N²)、、、といった感じで、直感的にわかりやすいかと思います。big(O)を測定する事は、さほど難易度は高く無いため、これを機にコードを実装する際は常にbig(O)を意識するようにして下さいね
O(1)のケース
まずは、もっとも基本的なケースのO(1)について解説をします。上記でも触れましたが、O(1)は、変数への値の代入、変数、リスト、dictの値の参照等の場合は、どれも一回の計算量で操作が完結するためO(1)となります。具体的には以下のような例です。

O(N)のケース
O(N)のケースに関しては、上記で説明をした通り、ループを一回回る処理となります。因みにO(N)のNは要素数を表していて、当然ながらリストの中の要素数に応じて、計算量は比例します。

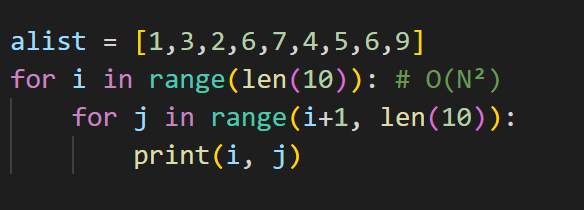
O(N²)のケース
こちらは、for文の中に、for文がネストしているようなケースです。O(N²)以上になると、計算量はかなり増えてしまうので、これ以上、for文がネストしてしまうようなコードは余り実装されない方がいいです。
また、O(N²)のコードをO(N)に計算量を減らす等の努力をされた方がいい場合もあります。その場合、新たにデータ構造を使用する事になる場合が多く、こちらは、計算量とメモリのトレードオフになります。こちらに関しては後程例をあげて解説します。
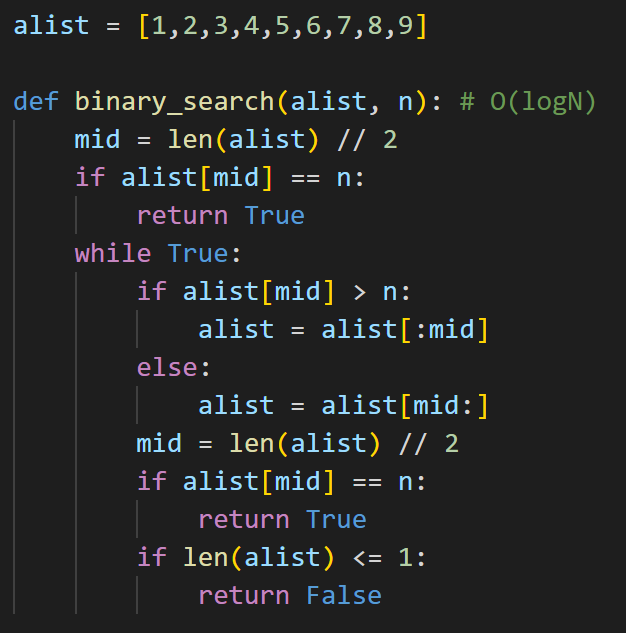
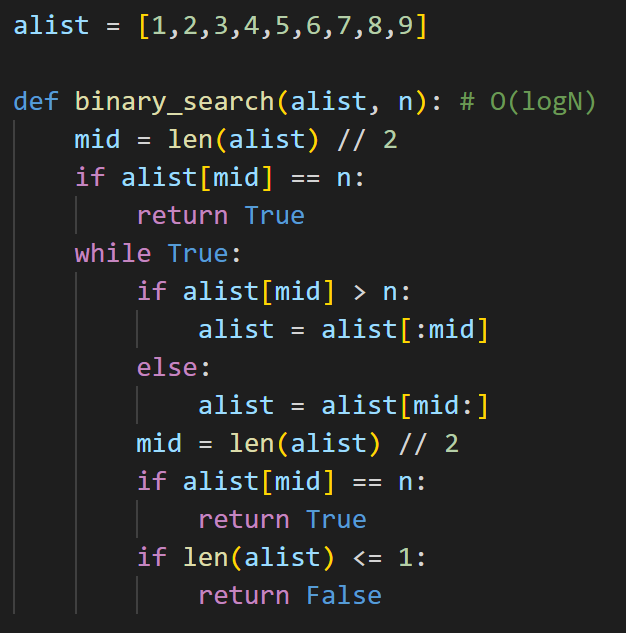
O(logN)のケース
O(logN)のケースに関しては、二分木探索等、検索回数が回を追うごとに半分毎に減るなどのケースです。logという言葉が出てくると、数学アレルギーの方は戸惑うかもしれないですが、あまり難しず考えず、探索量が半分ずつ減っていく場合にlogNなんだな。。。という感じで捉えて頂いて大丈夫です。
以下は、ソート済のリストに対して、二分木探索をした例です。コードの詳細についてはここでは触れませんが、whileループの中で、値の探索が徐々に半分ずつ狭まっているのがわかると思います。こういったソート済のリストの要素の探索や、木構造の探索等はlogNとなります。
探索アルゴリズムにおけるbig(O)の有用性
ここまでbig(O)について解説を進めてきて、概念は理解したけどいまいちこれはどう実務に応用できるのかぴんときていない方もいるかもしれませんね。そのため、非常に身近な例をあげて、big(O)の有用性を開設します。普段、どの分野でも、値の重複を確認するプログラムは皆様実装されているかと思いますが、その際に、リストや、セット等に値を格納して、in演算子で、値が既にあるかどうかを確認するようなコードを実装する機会は多いと思います。
さて、それでは、実際に以下の2つのコードを眺めてみましょう。皆様、この場合、どちらの探索が早いか、またその理由はわかりますでしょうか?
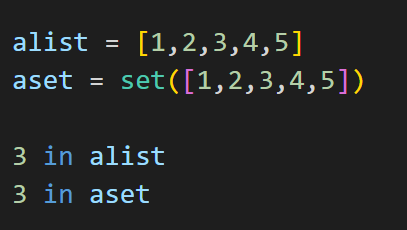
私自身がコーディングインタビューを行う際、必ずこの問題を最初に質問してから、本番のコーディングインタビューに進むのですが、ショッキングな事に、この問題を正しく回答できる人は殆どいないのです。。。こういった値探索のケースは実務でも多いと思うので、絶対に抑えておくポイントの1つになります。特にデータエンジニアや、データサイエンティストは必ずしっておきましょう
正解は、リストの探索がO(N)で、セットの探索がO(1)です。そのため、単純な値の検索だけならセットの方が遥かに高速なので、膨大なデータを探索する場合は、セットを使用した方がかなり効率が良くなります。なぜセットはO(1)なのかというと、セットは値を格納する時、その値のハッシュ値を計算し、それをメモリのアドレスに直接紐づけるので、O(1)となるのです。同様に、dictのキーの検索もO(1)となるので、必ず覚えておきましょう。
big(O)の計算量を下げるための工夫
上述の通り、O(N²)のコードをO(N)に計算量を減らす等の努力は、コードの実行時間を短縮するため非常に有用です。こちらに関しては実際に例を見て頂くのが一番わかりやすいかと思いますので、以下の課題について取り組んでみたいと思います。
- リストに格納された値の中に重複値があるかどうかを確認するコードを実装しなさい
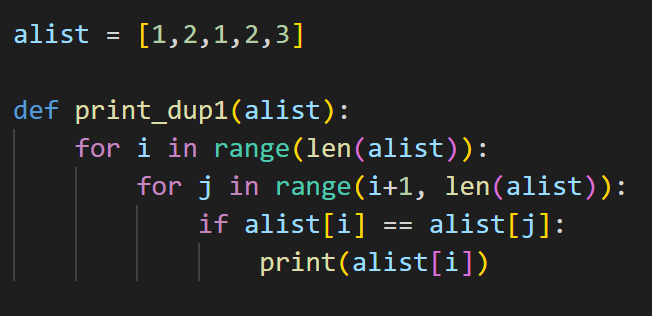
O(N²)のソリューション
まずは、こちらをforループを2回回す、O(N²)で解いてみます。以下のコードではalistのサイズが小さいならば特に問題はないのですが、サイズが大きくなると計算量も指数関数的に増大するため、時間がかかる処理となります。
O(N)のソリューション
次に、同じ問題をO(N)で解いてみます。この場合は、新たにデータ構造を追加し、そこに値を足していき、値が既にあれば重複とみなすというコードになります。ここで重複確認用データ構造はリストでなく、セットを使用している理由は、もうおわかりですね?

この場合は、計算量はO(N)になり改善されたのですが、新たにセットを追加した事で、その中にデータが格納され、メモリは余計に消費されてしまっています。このように、big(O)の改善は、メモリと計算量のトレードオフになる事が多いので、環境や条件に合わせて適切に選択をする必要があります。
また、この点を正しく面接官に伝えることができると良いアピールになります!
まとめ
今回は、コーディングインタビューに挑むにあたって、必ず押さえておく必要がある項目の1つのbig(O)について実例を交えて簡単に解説をさせて頂きました。また、計算量とメモリのトレードオフについても解説を行いました。
big(O)を意識する事は、普段の業務でも非常に重要なので、今まで意識をされていなかった方は、これを機に意識をしてみてください。