検索精度の指標「適合率」と「再現率」
検索精度の指標「適合率」と「再現率」
前回の投稿では、ステミング、類義語(同義語)拡張等、自然言語処理でよく使われる基本的なテクニックについて紹介を行い、それらのテクニックがどのように全文検索のヒット率に貢献するかを説明させて頂きました。
その中で、類義語(同義語)拡張等のテクニックにより、全文検索のヒット率が増加する事は説明しましたが、それにより、本来は意図していないようなドキュメントが返却されてしまう事もある弊害についても説明を行いました。
今回は、上述の全文検索のトレードオフの関係を、「再現率」と「適合率」という言葉を用いて解説をしていきます。
適合率と再現率
情報検索システムの検索性能の評価を行う。情報検索システムの検索性能は主に正確性と網羅性の質的な観点から適合率(precision;精度ともいう)と再現率(recall)を、処理性能の量的な観点からスループットを測定することにより判定するのが一般的である。
※日本語Wikipediaより引用
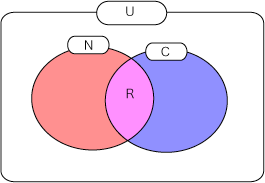
上記が、日本語Wikipediaの「情報検索」に関する記事の中の、「検索性能の評価」というセクションの内容です。正直、何の事をいっているのかさっぱりわからないかと思いますが、情報検索では「正確性」と「網羅性」という指標を評価に用いている事がわかるかと思います。これらに関して、以下もう少し噛み砕いてお話をします。まずは、以下の図を御覧ください

上の図の各アルファベットの文字は以下を指しています。例によって、ユーザが「人工知能」という検索キーワードを検索エンジンに入力していると仮定して、説明を行います
- U:検索エンジン中にインデックスされているドキュメント全て
- N:ユーザが「人工知能」というキーワードで検索した際に返却された結果全て
- C:検索エンジン中にインデックスされている「人工知能」に関するドキュメント全て
- R:ユーザが「人工知能」というキーワードで検索した際に、正しく「人工知能」に関連するドキュメントが取得できた部分
適合率(precision):正確性の指標
まずは、適合率の説明から行います。適合率は、上の図のNの円の中のRの割合で決定します。この説明ではちんぷんかんぷんだと思いますので、もう少し掘り下げてみます。さて、上の図のNはユーザが「人工知能」というキーワードを入力した際に、返却された全てのドキュメントを表しています。その中で本当に「人工知能」の内容を含んだドキュメントがRとなります。つまり、これを小学生でも理解できる簡単な数式で表現すると以下となります。
- 適合率:R ÷ N
これが、適合率は正確性の指標だという根拠で、ユーザが検索を行って得た結果が、どれくらいユーザの意図したものに近いかどうかを判定する指標と言えます。
前回の投稿で紹介をさせて頂いた、「固有表現抽出」技術等は、固有表現を正しく認識する事で、結果の正確性をあげる事に繋がるので、適合率をあげるためのテクニックという事ができます。
再現率(recall):網羅率の指標
次に再現率の説明を行います。再現率は、上の図のCの円の中のRの割合で決定します。こちらも、また噛み砕いて説明をしていきます。上の図のCは、検索エンジンの中に元にインデックスされているドキュメントの中で「人工知能」に関連するドキュメントの全てで、Rはユーザが検索を行って、結果を取得できた部分です。同様にこちらを簡単な数式で表現してみます。
- 再現率:C ÷ N
つまり、再現率は検索エンジンに元々インデックスされている(この場合は)「人工知能」のドキュメントのうち、どの位のドキュメントがユーザに返却されたかを測定する指標なので、むしろ網羅率と表現する方が正解となります。
前回の投稿で紹介をさせて頂いた、「ステミング」「類義語(同義語)拡張」等は、より多くのドキュメントを検索するために用いるテクニックなので、再現率の増加に繋がります。
適合率と再現率のトレードオフ
さて、前回の投稿で書いた、全文検索のヒット率をあげれば、ゴミのドキュメントが混ざってしまうため正確性が下がり、検索結果の正確性を上げれば、拾えるドキュメントの数は限定されてしまうため、検索結果の網羅率が下がってしまいます。こちらがまさに、適合率と再現率のトレードオフの関係そのものとなります。一般的に適合率と再現率の関係は以下のような図で表されます。

上の図のPrecisionは適合率、Recallは再現率を表していますが、明らかにどちらかの値が上昇すれば、どちらかが減少するという関係になっています。理想的にはこの2つの曲線が交差する点が適合率と再現率がバランス良く考慮されている点となっています。
適合率と再現率のどちらが大事かという議論に関しては、一意に答えが定まる話ではありません。仮に、常に正しい検索結果が必要な場合は、適合率の方が重要な指標になりますし、とにかく幅広く色々なドキュメントが必要な場合は、再現率の方が重要な指標となります。
F値
上述の通り、適合率と再現率はトレードオフの関係にあり、このどちらかが上昇すれば、どちらかが減少するという関係にあります。このどちらかの指標の方がより重要になる場面はケース・バイ・ケースなのですが、どちらの指標も加味したいという場合もあると思うので、そこで用いられる指標がこのF値です。
F値の具体的な計算の仕方に関しては、数式が少々複雑になるため割愛しますが、適合率と再現率の療法が加味されており、このF値が最大になる時が、一般的に良い値とされています。
まとめ
本投稿では、情報検索にとって重要な指標である、適合率と再現率について説明をし、その2つの値のトレードオフの関係についても解説を行いました。適合率と再現率のどちらが重要かはケース・バイ・ケースで変化し、その2つの指標を考慮したF値という指標がある事も解説を行いました。
これらは、今まで解説を行ってきた全文検索や、今後解説を行っていく、機械学習等で重要な指標になるので、イメージだけは把握して頂ければ幸いです。